Email Bomb
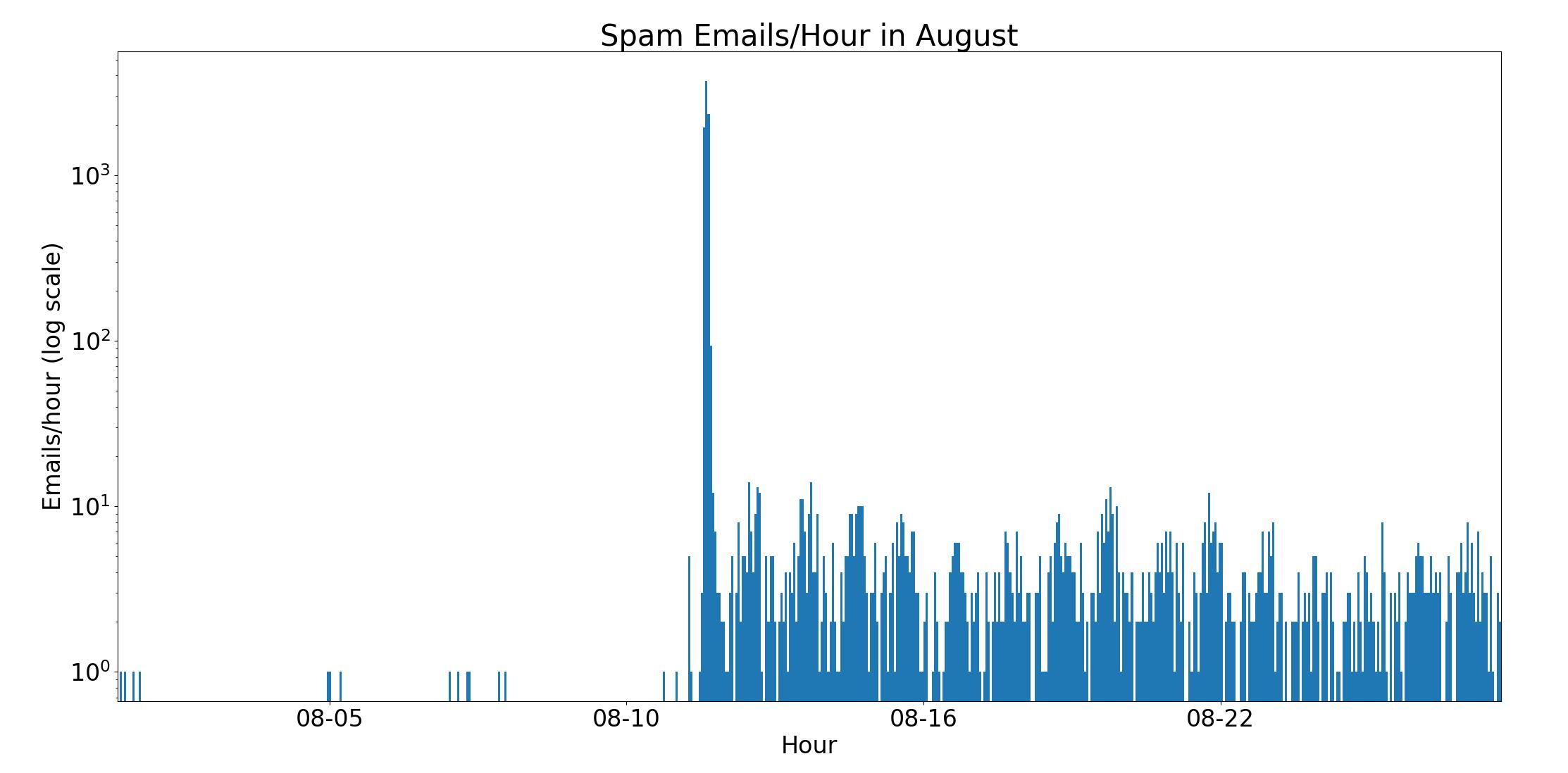 On August 12, for about 24 hours my email inbox was flooded with emails, peaking at over 1 email/second. This type of attack is known as an email bomb, and the intent is to overwhelm email providers and/or user attention as cover for other simultaneous attacks (which might send emails from password changes, online purchases, etc.).
On August 12, for about 24 hours my email inbox was flooded with emails, peaking at over 1 email/second. This type of attack is known as an email bomb, and the intent is to overwhelm email providers and/or user attention as cover for other simultaneous attacks (which might send emails from password changes, online purchases, etc.).
The attacker did not use their own computing resources to send emails - instead, the attacker had a list of mailing lists, and used a script to subscribe my email address to each one. Each mailing list then sent me a welcome email. This makes email bombs difficult to prevent, as there’s no single source to block, and furthermore many of these mailing lists belong to legitimate businesses.
Although the attack occurred many weeks ago, I’m still an unwitting member of these countless email lists, and have received a steady stream of unwanted daily newsletters, promotional offers, blog posts, etc. Most of them do go to the spam folder, but that still means any attempt to search for legitimate emails in my spam folder is difficult. So to address this, I’m going to write some code to click on all the unsubscribe links in emails in my spam folder.
Downloading Emails
Email data can be easily downloaded via the gmail api. I’ll be using the Python version. The first step is to get a gmail api service object, which can just be copied from the quickstart tutorial code and will likely end in something like this.
service = build('gmail', 'v1', credentials=creds)
Next let’s figure out the email label id corresponding to the spam folder.
labels = service.users().labels().list(userId='me').execute().get('labels', [])
spam_label_id = next(label['id'] for label in labels if label['name'] == 'SPAM')
Each email is referenced by a message object, and we can only request a page of messages at a time. Each response provides the necessary information to request the next page, so we use a loop to accumulate up the messages.
def getMessagesWithLabels(service, user_id, label_ids):
response = service.users().messages().list(userId=user_id,
labelIds=label_ids).execute()
messages = []
if 'messages' in response:
messages.extend(response['messages'])
while 'nextPageToken' in response and not DEBUG:
print('\rFound %d messages' % len(messages), end='') # carriage return to overwrite
page_token = response['nextPageToken']
response = service.users().messages().list(userId=user_id,
labelIds=label_ids,
pageToken=page_token).execute()
messages.extend(response['messages'])
print() # new line after carriage returns
return messages
min_messages = getMessagesWithLabels(service, 'me', [spam_label_id])
These message objects only contain identifiers - getting any actual email information requires making further queries using those ids. Before downloading the full message bodies, let’s first try grabbing some basic metadata.
# The data we will gather
data = [['epoch_ms', 'from', 'reply-to', 'subject']]
# The callback for each message
def getMsgData(rid, message, exception):
if exception is not None:
return
epoch_ms = int(message['internalDate'])
fromx = ''
reply_to = ''
subject = ''
headers = message['payload']['headers']
for h in headers:
if h['name'] == 'From':
fromx = h['value']
elif h['name'] == 'Reply-To':
reply_to = h['value']
elif h['name'] == 'Subject':
subject = h['value']
data.append([epoch_ms, fromx, reply_to, subject])
# Batching requests is faster
batcher = service.new_batch_http_request()
for i, mm in enumerate(min_messages):
if (i % 100 == 0 and i != 0):
print(f'\rRequesting msg {i}', end='')
batcher.execute()
batcher = service.new_batch_http_request()
batcher.add(service.users().messages().get(userId='me', id=mm['id'], format='metadata'), callback=getMsgData)
print() # new line after carriage returns
# Handle last set
batcher.execute()
with open('data.csv', 'w') as f:
writer = csv.writer(f)
writer.writerows(data)
Email Rate
With this data in hand, we can make some plots. Here’s the rate of emails/hour over the entire month. Note the logarithmic y-axis.
Before August 12, I rarely received emails to the spam folder, and never more than 1/hour. Then, a surge of emails, reaching 3719 spam emails per hour at its peak. Afterwards, there’s a regular pattern to the email frequency, still far above the initial rate.
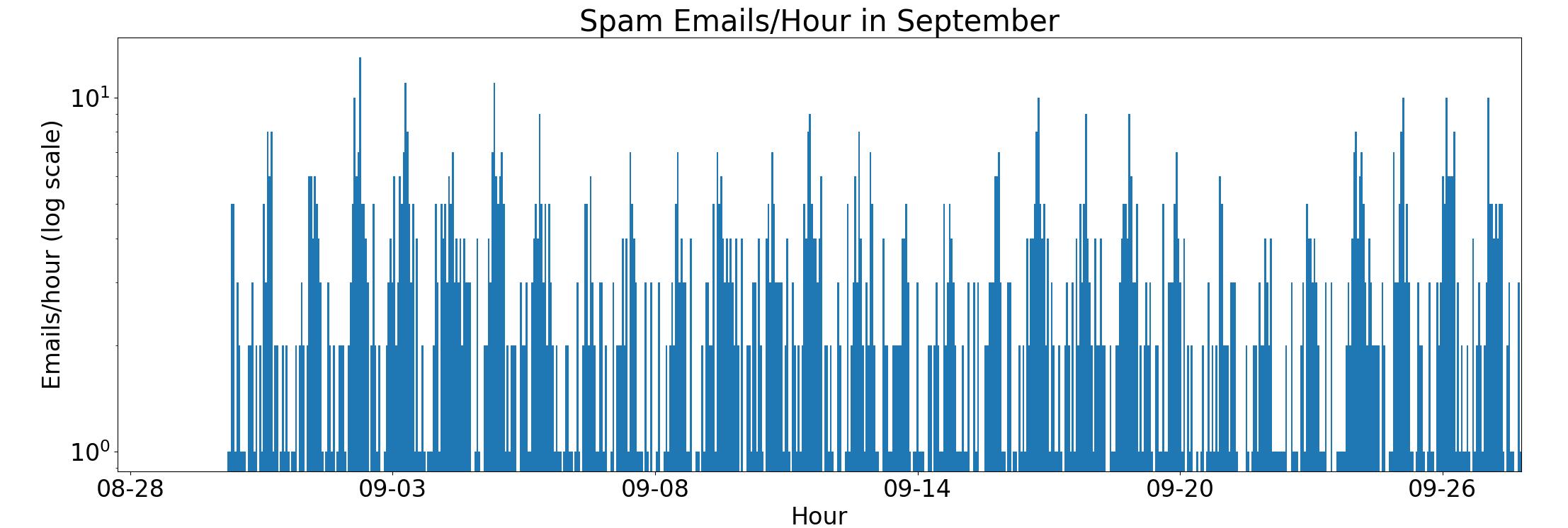 The rate and pattern hold fairly steady through September.
The rate and pattern hold fairly steady through September.
Who are the Offenders?
The emails I received on August 12 were mostly welcome emails. Because the volume of emails I receive now is significantly lower, it can be assumed that most mailing lists required subscription confirmation. Let’s see who is sending emails without subscription confirmation, based on September data. This isn’t that surprising, as the vast majority of lists are sending emails roughly once per weekday.
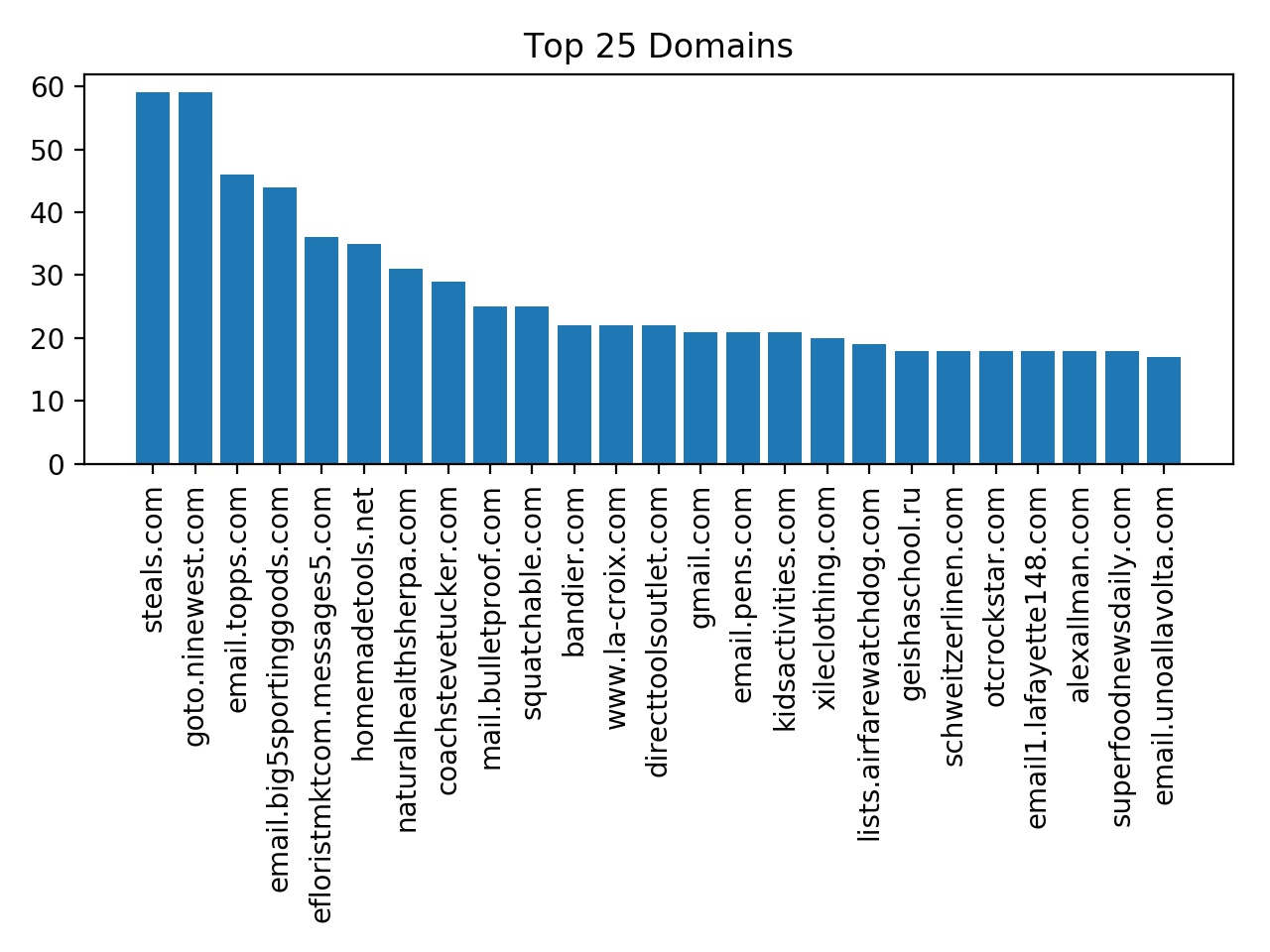
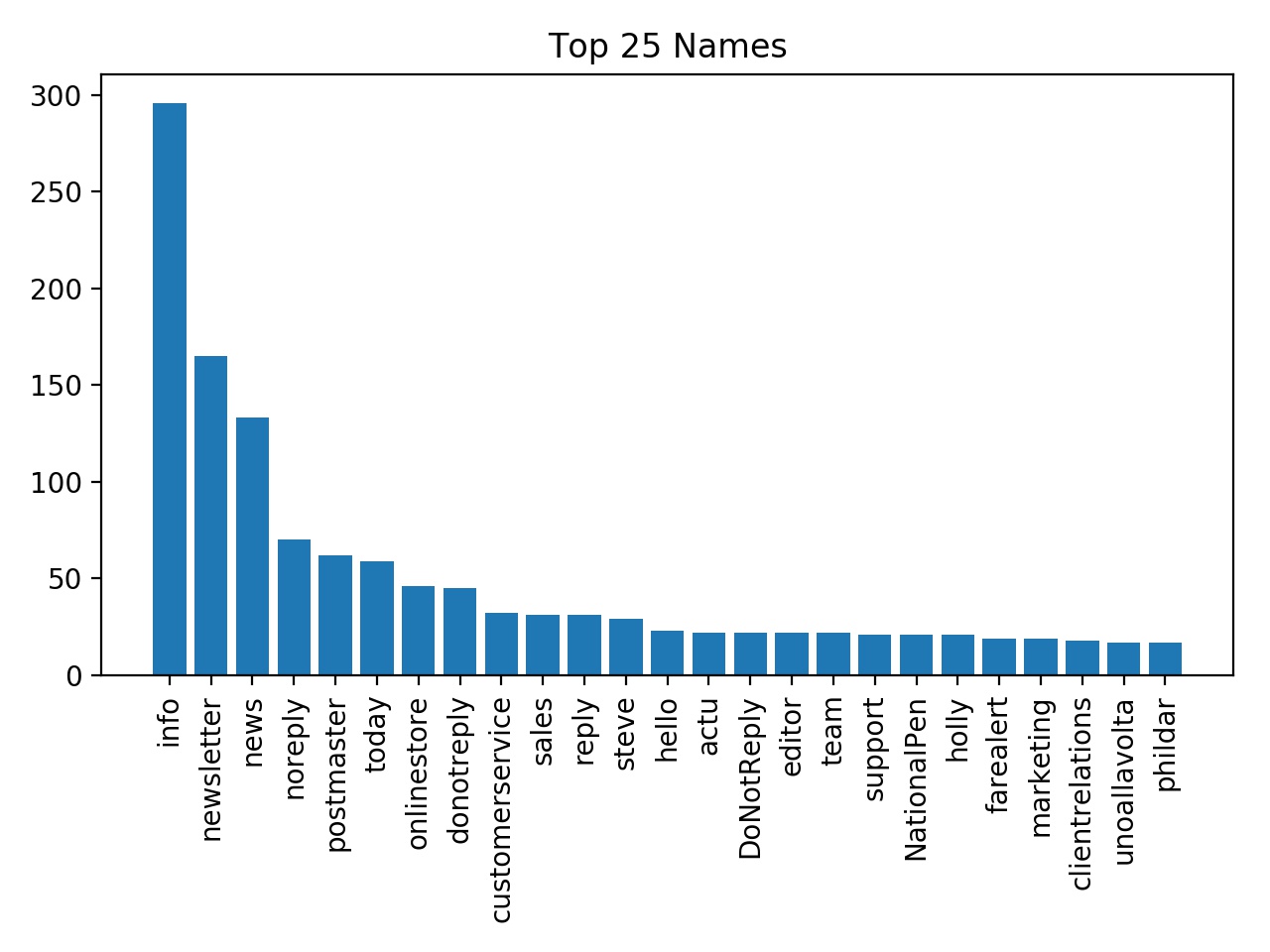 Also unsurprising, there’s not much variation in the email names, though I guess Steve and Holly are the most likely names for email marketers.
Also unsurprising, there’s not much variation in the email names, though I guess Steve and Holly are the most likely names for email marketers.
Automated Unsubscription
To actually unsubscribe, we’ll need to download each email’s contents, search for the unsubscribe link, and click on it. To get the full message body we need to update the message request to format='full'.
batcher.add(service.users().messages().get(userId='me', id=mm['id'], format='full'), callback=getMsgData)
The message contents as an html string can be obtained as follows
def getMsgData(rid, message, exception):
if exception is not None:
return
try:
msg = next(m for m in message['payload']['parts'] if m['mimeType'] == 'text/html')
except:
return
msg_data = msg['body']['data']
msg_html = base64.urlsafe_b64decode(msg_data.encode('ASCII')).decode('utf-8')
We’ll cast a wide net by collecting any and all links that contain “unsubscribe” in their text. Python’s built-in html parser steps through tags and the data between tags, so we can use it to extract all links fitting our criteria.
class UnsubLinkParser(HTMLParser):
a_href = ''
unsub_links = []
def handle_starttag(self, tag, attrs):
if tag == 'a':
for attr in attrs:
if attr[0] == 'href':
self.a_href = attr[1]
break
def handle_endtag(self, tag):
if tag == 'a':
self.a_href = ''
def handle_data(self, data):
if self.a_href != '' and 'unsubscribe' in data.lower():
self.unsub_links.append(self.a_href)
self.a_href = ''
With our links gathered up, we can simply visit each one in turn:
for link in parser.unsub_links:
urllib.request.urlopen(link)
Some unsubscribe links will require further action, such as clicking a ‘submit’ button. For now let’s ignore that, and see how effective this simple method is.
Edit from a week later: There’s been a decrease of around 10% or so. There seems to be 3 reasons for this. 1: Some sites require more than just the single button click. 2: Many messages occur less than once a month, meaning they weren’t in the spam folder (which gets auto-cleaned every 30 days) at the time of running my script. Running every week or so has continued to slowly decrease the email rate. 3: At least half of the current spam emails are not in english, meaning I need to compile a list of “unsubscribe” in other languages